%20for%20Image%20Classification_%20Performance%20Benchmarks.png?width=1000&height=556&name=Best%20Vision%20Language%20Models%20(VLMs)%20for%20Image%20Classification_%20Performance%20Benchmarks.png&w=1068&resize=1068,0&ssl=1 "Benchmarking Top Vision Language Models (VLMs) for Image Classification")
%20for%20Image%20Classification_%20Performance%20Benchmarks.png?width=1000&height=556&name=Best%20Vision%20Language%20Models%20(VLMs)%20for%20Image%20Classification_%20Performance%20Benchmarks.png "Benchmarking Top Vision Language Models (VLMs) for Image Classification")
%20for%20Image%20Classification_%20Performance%20Benchmarks.png?width=1000&height=556&name=Best%20Vision%20Language%20Models%20(VLMs)%20for%20Image%20Classification_%20Performance%20Benchmarks.png&w=1200&resize=1200,0&ssl=1&description=Benchmarking+Top+Vision+Language+Models+%28VLMs%29+for+Image+Classification){kind=link}
Introduction
In the rapidly evolving field of artificial intelligence, the ability to accurately interpret and analyze visual data is becoming increasingly crucial. From autonomous vehicles to medical imaging, the applications of image classification are vast and impactful. However, as the complexity of tasks grows, so does the need for models that can seamlessly integrate multiple modalities, such as vision and language, to achieve more robust and nuanced understanding.
This is where Vision Language Models (VLMs) come into play, offering a powerful approach to multimodal learning by combining image and text inputs to generate meaningful outputs. But with so many models available, how do we determine which one performs best for a given task? This is the problem we aim to address in this blog.
The primary goal of this blog is to benchmark Top Vision Language Models on an image classification task using a basic dataset and compare its performance to our general-image-recognition model. Additionally, we will demonstrate how to use the model-benchmark tool to evaluate these models, providing insights into their strengths and weaknesses. By doing so, we hope to shed light on the current state of VLMs and guide practitioners in selecting the most suitable model for their specific needs.
What are Vision Language Models (VLMs)
A Vision Language Model (VLM) is a type of multimodal generative model that can process both image and text inputs to generate text outputs. These models are highly versatile and can be applied to a variety of tasks, including but not limited to:
- Visual Document Question Answering (QA): Answering questions based on visual documents.
- Image Captioning: Generating descriptive text for images.
- Image Classification: Identifying and categorizing objects within images.
- Detection: Locating objects within an image.
The architecture of a typical VLM consists of two main components:
- Image Feature Extractor: This is usually a pre-trained vision model like Vision Transformer (ViT) or CLIP, which extracts features from the input image.
- Text Decoder: This is typically a Large Language Model (LLM) such as LLaMA or Qwen, which generates text based on the extracted image features
These two components are fused together using a modality fusion layer before being fed into the language decoder, which produces the final text output.
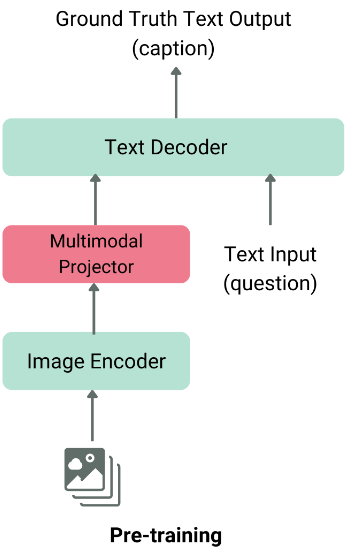
General architecture of vlm, image taken from hf blog.
There are many Vision Language Models available on the Clarifai Platform, including GPT-4o, Claude 3.5 Sonnet, Florence-2, Gemini, Qwen2-VL-7B, LLaVA, and MiniCPM-V. Try them out here!
Current State of VLMs
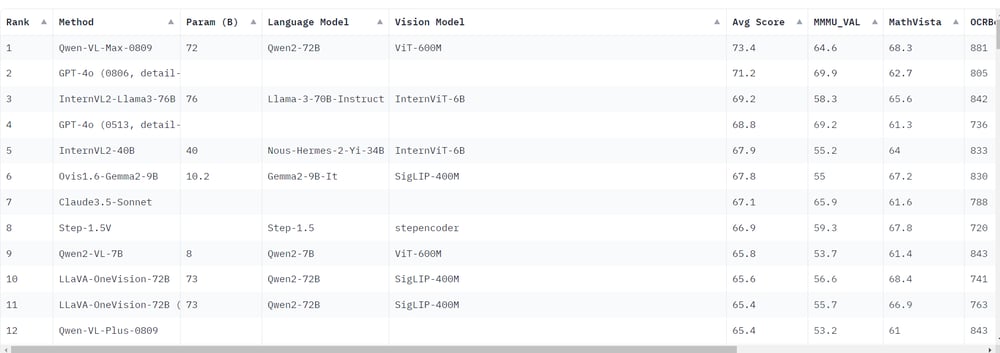
Recent rankings indicate that Qwen-VL-Max-0809 has outperformed GPT-4o in terms of average benchmark scores. This is significant because GPT-4o was previously considered the top multimodal model. The rise of large open-source models like Qwen2-VL-7B suggests that open-source models are beginning to surpass their closed-source counterparts, including GPT-4o. Notably, Qwen2-VL-7B, despite its smaller size, achieves results that are close to those of commercial models.
Experiment setup
Hardware
The experiments were conducted on Lambda Labs hardware with the following specifications:
|
CPU |
RAM (GB) |
GPU |
VRAM (GB) |
|---|---|---|---|
|
AMD EPYC 7J13 64-Core Processor |
216 |
A100 |
40 |
Models of Interest
We focused on smaller models (less than 20B parameters) and included GPT-4o as a reference. The models evaluated include:
|
model |
MMMU |
|---|---|
|
Qwen/Qwen2-VL-7B-Instruct |
54.1 |
|
openbmb/MiniCPM-V-2_6 |
49.8 |
|
meta-llama/Llama-3.2-11B-Vision-Instruct |
50.7 (CoT) |
|
llava-hf/llava-v1.6-mistral-7b-hf |
33.4 |
|
microsoft/Phi-3-vision-128k-instruct |
40.4 |
|
llava-hf/llama3-llava-next-8b-hf |
41.7 |
|
OpenGVLab/InternVL2-2B |
36.3 |
|
GPT4o |
69.9 |
Inference Strategies
We employed two main inference strategies:
- Closed-Set Strategy: We utilized standard metrics to benchmark these frameworks, including:
- The model is provided with a list of class names in the prompt.
- To avoid positional bias, the model is asked the same question multiple times with the class names shuffled.
- The final answer is determined by the most frequently occurring class in the model’s responses.
- Prompt Example:
“Question: Answer this question in one word: What type of object is in this photo? Choose one from {class1, class_n}. Answer: <model answer>“
- Binary-Based Question Strategy:
- The model is asked a series of yes/no questions for each class (excluding the background class).
- The process stops after the first ‘yes’ answer, with a maximum of (number of classes – 1) questions.
- Prompt Example:
“Answer the question in one word: yes or no. Is the {class} in this photo?“
Results
Dataset: Caltech256
The Caltech256 dataset consists of 30,607 images across 256 classes, plus one background clutter class. Each class contains between 80 and 827 images, with image sizes ranging from 80 to 800 pixels. A subset of 21 classes (including background) was randomly selected for evaluation.
|
model |
macro avg |
weighted avg |
accuracy |
GPU (GB) (batch infer) |
Speed (it/s) |
|---|---|---|---|---|---|
|
gpt4 |
0.93 |
0.93 |
0.94 |
N/A |
2 |
|
Qwen/Qwen2-VL-7B-Instruct |
0.92 |
0.92 |
0.93 |
29 |
3.5 |
|
openbmb/MiniCPM-V-2_6 |
0.90 |
0.89 |
0.91 |
29 |
2.9 |
|
llava-hf/llava-v1.6-mistral-7b-hf |
0.90 |
0.89 |
0.90 |
|
|
|
llava-hf/llama3-llava-next-8b-hf |
0.89 |
0.88 |
0.90 |
|
|
|
meta-llama/Llama3.2-11B-vision-instruct |
0.84 |
0.80 |
0.83 |
33 |
1.2 |
|
OpenGVLab/InternVL2-2B |
0.81 |
0.78 |
0.80 |
27 |
1.47 |
|
openbmb/MiniCPM-V-2_6_bin |
0.75 |
0.77 |
0.78 |
|
|
|
microsoft/Phi-3-vision-128k-instruct |
0.81 |
0.75 |
0.76 |
29 |
1 |
|
Qwen/Qwen2-VL-7B-Instruct_bin |
0.73 |
0.74 |
0.75 |
|
|
|
llava-hf/llava-v1.6-mistral-7b-hf_bin |
0.67 |
0.71 |
0.72 |
|
|
|
meta-llama/Llama3.2-11B-vision-instruct_bin |
0.72 |
0.70 |
0.71 |
|
|
|
general-image-recognition |
0.73 |
0.70 |
0.70 |
N/A |
57.47 |
|
OpenGVLab/InternVL2-2B_bin |
0.70 |
0.63 |
0.65 |
|
|
|
llava-f/llama3-llava-next-8b-hf_bin |
0.58 |
0.62 |
0.63 |
|
|
|
microsoft/Phi-3-vision-128k-instruct_bin |
0.27 |
0.22 |
0.21 |
|
|
Key Observations:
Impact of Number of Classes on Closed-Set Strategy
We also investigated how the number of classes affects the performance of the closed-set strategy. The results are as follows:
|
model | Number of classes |
10 |
25 |
50 |
75 |
100 |
150 |
200 |
|---|---|---|---|---|---|---|---|
|
Qwen/Qwen2-VL-7B-Instruct |
0.874 |
0.921 |
0.918 |
0.936 |
0.928 |
0.931 |
0.917 |
|
meta-llama/Llama-3.2-11B-Vision-Instruct |
0.713 |
0.875 |
0.917 |
0.924 |
0.912 |
0.737 |
0.222 |
Key Observations:
- The performance of both models generally improves as the number of classes increases up to 100.
- Beyond 100 classes, the performance starts to decline, with a more significant drop observed in meta-llama/Llama-3.2-11B-Vision-Instruct.
Conclusion
GPT-4o remains a strong contender in the realm of vision-language models, but open-source models like Qwen2-VL-7B are closing the gap. Our general-image-recognition model, while fast, lags behind in performance, highlighting the need for further optimization or adoption of newer architectures. The impact of the number of classes on model performance also underscores the importance of carefully selecting the right model for tasks involving large class sets.